Multiple Granularity in DBMS
Granularity, in simple terms, refers to the size and precision of data objects within a DBMS. The more granular a system is, the more precise its data objects will be.
In general, there are two types of granularity: single-level and multiple-level.
- Single-level granularity refers to a DBMS in which all data objects have the same level of precision.
- Multiple-level granularity refers to a DBMS in which different data objects have different levels of precision.
Multiple granularities allow the storage of different levels of detail in a single system. For instance, if the system includes employee data, then we can store basic information like name and position at a “coarse” level and more detailed information like age and salary at a “fine” level. This
way, depending on the needs, can query either level of data as needed.
Multiple granularities also provide scalability—the ability to adjust the system as needed in order to accommodate new or different data sets. This is important for growing businesses that may need to store additional or new types of data without having to revamp their entire database system.
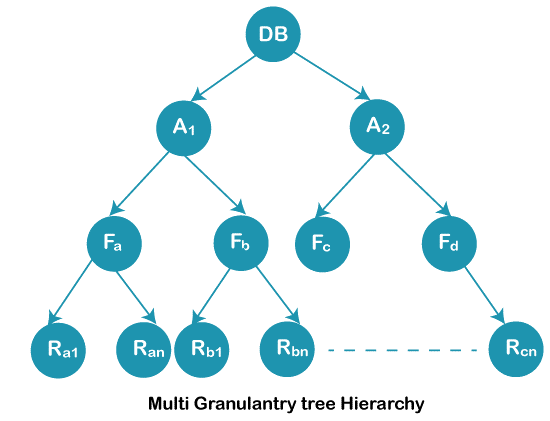
Below is the representation of multiple granularities tree hierarchy:
Advantages of Multiple Granularity in Database Management Systems
There are three primary advantages that make using multiple granularities beneficial for database management systems:
- Scalability: Using multiple granularities allows for greater scalability in the database—which is especially important for faster- growing businesses or data applications. It ensures the performance of the system can be managed effectively across all levels, thus ensuring smooth operation and high performance.
- Improved Data Security: By introducing multiple granularities into the system, it's possible to establish different levels of security that control access to certain parts of the database. This ensures user access is restricted to only what they need to achieve their particular tasks and prevents unauthorized users from accessing sensitive data.
- Faster Processing: By having a range of different granularities in place, different tasks can be balanced over different parts of the system, allowing greater optimization and faster response times when querying data or running other operations. This leads to better resource usage and enhanced overall efficiency in terms of processing power used versus results achieved.
Disadvantages of Multiple Granularity in Database Management Systems
Some of the disadvantages are given below:
Update Anomalies
When data is stored at multiple granularity levels, it can lead to updating anomalies. For example, when you update information or a record that’s stored at a low granularity level, there may be some data disparities when the same data is retrieved from a higher granularity level. This can be very confusing for users and lead to inconsistencies in the database.
Redundancy of Data
Another disadvantage of multiple granularity levels is that it can lead to the redundancy of data. For example, if you have data stored at both a low and high granularity level, there might be duplicate records due to different interpretations of the same data. As you can imagine, this leads to unnecessary storage requirements and extra overhead work for the database administrator or user.
Lack of Flexibility
Lastly, when using a multiple granularity system, database users often find lack of flexibility because they are locked into certain levels or categories of data. This means that they are unable to query the database in certain ways because the database structure is tailored towards those specific levels or categories.
Examples of Multiple Granularity in Database Management Systems
When it comes to database management systems, one important concept to understand is multiple granularities. It’s important to understand what this means and how it applies to databases, so here are some examples.
Relational Databases
Relational databases are those that use tables and rows to store data in relational form. Each row is considered a single entity, with each field representing an individual attribute of the entity. That single row then can be broken down into multiple granularities. For example, a customer table might be broken down into individual customer fields like name, address, and email address; or it could represent the entire customer record by having columns such as orders placed and the total value of orders. In either case, the table can be adjusted to match the granularity needed for any queries or reports.
Graph Databases
Graph databases are those that use nodes and edges to represent relationships between entities in a database. They can also be broken down into multiple granularities depending on how nodes and edges are configured. For example, a graph could always depict two entities as connected by an edge or it could further divide the graph by assigning additional data points regarding the relationship between them such as when they connected or what type of connection they had.
Intention Mode Lock in Multiple Granularity in DBMS
Multiple granularities is when low-level locks are applied to parts of data entities, rather than to the entire entity (which would be coarse-grained locking). For example, using intention mode locks, we can lock down an entire table, so no one can use it until it is done.
Intention Mode Locks
Intention mode locks are either Shared or Exclusive. With Shared intent, other transactions can acquire shared access to the locked object (or objects) without blocking each other, but cannot acquire exclusive access. With Exclusive intent, only one transaction can update the locked object(s) at any given time – and only that transaction is allowed to modify or query the data until the lock is released. Basically, it means setting up access for groups of transactions that need to update certain parts of a database table simultaneously – but not all of them at once.
Maintaining Consistency and Integrity in databases
Multiple granularities helps preserve the integrity of data by preventing different processes from changing or overwriting tables and records at the same time. It ensures that each process has exclusive access to exactly what it needs while allowing other users to still query tables and records which are not affected by that process activity.
Using this method of low-level locking with intention mode controls helps maintain consistency while allowing multiple users to read/write functions simultaneously. Intention mode locks also help prevent deadlocks.
Unlocking Multiple Granularity in DBMS
At its most basic, multiple granularities refers to a DBMS's ability to store information at different levels of detail or abstraction. This is important because different applications and users require different levels of detail, and the same data can be displayed and manipulated in various ways. For instance, a healthcare application might need to store patient medical history at a very detailed level, while an insurance provider might only need basic patient information for tracking purposes.
In order to unlock multiple granularity in DBMSs, there are three main components:
- Data Modeling: This is the process of designing a data model that facilitates the creation and manipulation of data at multiple levels of abstraction. This involves deciding on appropriate tables, relationships between those tables, and so on.
- Indexing: The indexing process involves creating rules that make it easier for the DBMS to quickly retrieve data from stored records.
- Schema Refinement: Schema refinement helps optimize query performance by identifying patterns in the underlying data structure and using them to create more efficient database architecture.
By utilizing these components, DBMS can accurately store data at different granularity levels, allowing users to access and manipulate the information they need without having to sift through massive amounts of irrelevant data or create complex queries each time they want something specific.
Locking Multiple Granularity in DBMS
In database management systems, locking occurs when two or more transactions try to access the same resources, like records in a table. Locking at the highest level prevents further transactions from accessing these records until the first transaction is finished.
However, this can lead to lower concurrency and reduce the performance. That's where multiple granularities comes in. By using different levels of locks for different types of operations, one can increase concurrency and improve performance.
For example, if one transaction needs to read records from a table while another needs to write to it, we can use multiple granularity locks so that each transaction can happen at the same time without conflicts.
Moreover, there are different types of locks used with multiple granularities: shared locks allow multiple transactions to read data simultaneously; exclusive locks allow only one transaction at a time; and so on. With these various levels of lock protection combined with appropriate isolation levels, DBMSs can achieve better concurrent operation and improved performance.
Conclusion
In summary, multiple granularities can be a huge asset to any database management system. It offers the ability to partition tables into smaller pieces, making it easier to manage, modify, and query large amounts of data. Along with its ability to perform more specific operations, it also increases the efficiency of the database operations by allowing for more granular access control. Further, multiple granularity helps with compatibility - as different systems can support different granularities depending on the need, which prevents having to make huge changes to the system. Finally, it offers a secure way of processing data, as it allows for more detailed security measures and access control.
Overall, it is an important feature that can help database systems become more efficient and secure, and should be considered an essential feature for any system that needs to handle large amount of data.