Distributed DBMS
Introduction
A distributed database management system (DBMS) divides the database into smaller partitions or fragments that are kept on various nodes or servers over a network. Each node may have a separate local instance of a DBMS, and these instances work together to give users and applications a unified view of the database. Increased scalability, which enables managing more significant volumes of data and accommodating more users and applications, is one advantage of distributed DBMS. It also offers fault tolerance by replicating data or storing it redundantly across several nodes. This maximizes availability and reduces the possibility of data loss or service outages.
Although maintaining data consistency in a distributed setting can be difficult, DBMS use strategies like distributed locking, concurrency control, and transaction coordination.
Since it shields users and applications from data replication and dissemination difficulties, transparency is a crucial feature of distributed DBMS. It ensures that users are not required to be aware of the database's distributed architecture or its physical store location.
Features of Distributed DBMS
- Distribution of Data:
A distributed DBMS divides or separates the data into smaller pieces, storing each component on one or more network nodes.
- Replication:
Replication ensures that data is still accessible even when specific network connections or nodes fail.
- Data Transparency:
Users and programs may view and modify the data as if it were stored on a single system thanks to distributed DBMS, which offers transparency to users and applications. Users must be aware of the network complexity and underlying data distribution.
- Distributed Query Processing:
The DBMS optimizes query execution by dividing query processing responsibilities across many nodes. Retrieving and integrating results may entail concurrent query execution, data transport, and coordination among nodes.
- Concurrency Control:
Controlling concurrency is a difficulty for distributed systems because it affects preserving data integrity and managing concurrent access. To protect data integrity, distributed DBMS uses various concurrency control techniques such as locking, timestamp ordering, or optimistic concurrency control.
- Distributed Transaction Management:
To preserve the ACID (Atomicity, Consistency, Isolation, Durability) features, transactions involving several nodes must be coordinated. To ensure that distributed transactions are successfully performed, distributed DBMS adopt protocols like two-phase commit (2PC) or three-phase commit (3PC).
- Recovery:
A distributed database management system (DBMS) includes procedures for handling node failures, network partitions, and inconsistent data. It could use techniques like replication, backup and restore, distributed logging, and checkpointing to guarantee data durability and recoverability.
- Performance and Scalability: To manage big data volumes and a high number of concurrent users, distributed DBMS must have strong performance and scalability. In this field, solutions for horizontal scalability, distributed caching, load balancing, and performance tweaking are used.
- Maintenance: Maintaining data consistency in replicated databases is difficult because of replication. In order to guarantee consistent data across copies, this subtopic examines methods such as quorum-based protocols, anti-entropy protocols, and dispute-resolution algorithms.
- Data Partitioning and Placement: For effective data retrieval and storage, it is crucial to determine how data is partitioned and distributed across various nodes. Partitioning tactics, data migration methods, and dynamic data placement algorithms are all covered in this subtopic.
- Security: A significant challenge is guaranteeing security and privacy in distributed databases since data is spread across several nodes. Access control methods, authentication procedures, encryption methods, secure communication protocols, and privacy-preserving data processing are all covered under this subtopic.
Types of Distributed DBMS
Depending on its architectural layout and data dissemination methods, distributed database management systems (DBMS) come in a variety of shapes and sizes. Here are four varieties that are well-known:
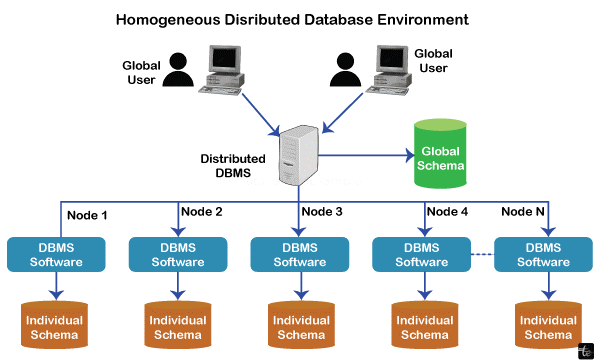
- Homogeneous distributed DBMS: It is one that uses the same DBMS software and schema across all database nodes. Multiple nodes are used to spread the data, and each node is free to independently carry out local transactions. To guarantee data coordination and consistency, the nodes talk to one another.
- Heterogeneous dispersed DBMS: Different DBMS programs and schema are employed by the dispersed nodes in a heterogeneous distributed DBMS. This kind of technology enables interoperability across diverse data sources and platforms by allowing integration and communication between distinct database types.
- Multiple autonomous and independent databases: each with its own DBMS software and schema, make up a federated distributed DBMS. For users and apps, they are logically combined into a single unified view. The proper databases receive queries and transactions, which are then aggregated and provided as a coherent answer.
- Cloud Distributed DBMS: A cloud computing infrastructure-based distributed database management system (DBMS) that offers scalability, flexibility, and on-demand resource provisioning. It entails setting up a distributed database over several cloud-hosted nodes or data centers.
Architecture of Distributed DBMS
Here is a high-level description of a distributed DBMS's architecture:
- Client/Server Architecture: Clients (user applications or other systems) and the server interact to access and alter data in a distributed database management system (DBMS). The server is in charge of overseeing the distributed database and organizing activities among various nodes.
- Multiple database nodes, which can be found on various computers or even in various places around the world, make up a distributed database. Each node works locally and saves a piece of the data.
- Global Catalog/Data Dictionary: The distributed DBMS maintains a central repository known as the global catalog or data dictionary. It keeps track of the distributed database's schema details, data locations, access rights, and distribution information in its metadata. The data dictionary supports query and transaction optimization.
- Query Decomposition and Optimization: When a client sends a query to a distributed database management system (DBMS), the query is divided into smaller queries that may be processed on several nodes. Then, utilizing local data and indexes, each sub-query is optimized locally. The goal of the optimization step is to increase query performance while minimizing data transmission.
- Execution and Coordination of Queries: After the subqueries have been optimized, they are run simultaneously on the relevant database nodes. The distributed DBMS manages transaction management, handles data consistency, coordinates the execution of subqueries, and resolves any dependencies or conflicts that may occur.
- Concurrency Control: Concurrency control technologies are used to manage concurrent access by numerous users or transactions to the distributed database. To guarantee data consistency and avoid conflicts, methods like distributed locking, timestamp ordering, or optimistic concurrency management are utilized.
- Communication and Data Transmission: To facilitate communication and data transmission between the client, server, and distributed nodes, communication channels, and protocols are used. This involves coordinating transactions, transmitting and receiving data subsets, and sharing query plans.
- Fault tolerance: Distributed DBMS must have fault tolerance and recovery capabilities in order to be reliable. Replication, distributed transaction management, backup and restore processes, failure detection, and handling of errors are just a few of the mechanisms for fault tolerance and recovery that are put into place.
- Security Mechanism: Distributed DBMS employs security mechanisms to safeguard the confidentiality and integrity of the data. This comprises secure communication protocols, access control, encryption, and authentication systems.
Applications of Distributed DBMS
- Cassandra is a distributed database management system (DBMS) built to handle massive volumes of data across several nodes and is extremely scalable and fault-tolerant. It offers configurable consistency levels, linear scaling, and good availability. Applications like social media, the Internet of Things, and real-time analytics, which demand high write throughput and continuous availability, frequently employ Cassandra.
- A well-known distributed NoSQL DBMS, MongoDB offers great scalability and adaptable data formats. By sharing data among several nodes and enabling automated sharding, it enables horizontal scaling. MongoDB is frequently used in applications like content management systems, mobile apps, and e-commerce platforms where data structure flexibility and real-time data processing are crucial.
- Google Spanner is a substantially consistent, globally distributed database management system. It offers high availability, ACID transactions, and global scalability across several data centers. Google uses Spanner for a number of mission-critical applications, and it is appropriate for use cases requiring robust consistency, global replication, and horizontal scalability.
- Cockroach DB is an open-source distributed SQL database with distributed ACID transactions, high consistency, and horizontal scalability. It offered comparable global scalability and fault tolerance features and was inspired by Google Spanner. Cloud-native apps, multi-region deployments, and micro-services architectures all often employ Cockroach DB.
- A distributed database management system (DBMS) that works with MySQL and PostgreSQL is provided by Amazon Web Services (AWS). It offers scalability, automated replication, and high availability across many availability zones. Organizations using AWS infrastructure for their applications frequently employ Aurora, which is intended for cloud-based applications.
- Cosmos DB is a worldwide distributed database management system (DBMS) provided by Microsoft Azure. It offers multi-region scalability, high availability, and guaranteed low latency and supports various data types, including document, key-value, graph, and columnar. Cosmos DB offers thorough SLAs for throughput, availability, and consistency and is appropriate for large-scale applications.
Advantages of Distributed DBMS
Compared to conventional centralized DBMS, distributed DBMS has a number of benefits. The following are some significant benefits of distributed DBMS:
- Increased Performance: Distributed DBMS can increase performance by distributing the database over numerous nodes or servers. Faster data access and query execution are made possible by this, which enables parallel processing and load balancing. Distributed DBMS can decrease latency and boost overall system response time by spreading data closer to the point where it is needed.
- High Scalability: By adding additional nodes to the system, distributed DBMS may quickly grow horizontally. Additional servers can be added to accommodate the growing burden as data and user demands increase. Distributed DBMS can handle vast volumes of data and support increasing users thanks to its scalability without encountering performance loss.
- Increased Availability and Fault Tolerance: By duplicating data over several nodes, distributed DBMS offers high availability and fault tolerance. The data may still be retrieved from other nodes in the system even if one of them fails or becomes unavailable. This redundancy increases overall system dependability by ensuring that the system continues functioning despite faults or outages.
- Improved Data Locality: Distributed DBMS enables data to be processed and stored closer to its location of need. This can be especially useful in geographically dispersed contexts or for applications with specialized data locality requirements. Distributed DBMS can optimize performance for applications that depend on accessing data from specific locations by reducing data transfer and network latency.
- Increased Data Security: Distributed DBMS may increase data security by adding access control and encryption techniques. Multiple nodes may be used to split and store data, and various individuals or groups may be given access at various levels. This decentralized strategy improves data privacy and security control while lowering the chance of unauthorized access.
- Geographical Flexibility: Data may be stored and retrieved from various places thanks to distributed databases. This is extremely helpful for businesses with spread operations or a global presence. Distributed DBMS facilitates smooth communication and data exchange across geographically dispersed teams by offering a single view of the data across several locations.
Cost-Effectiveness: In some situations, distributed DBMS can be more cost-effective than centralized DBMS. Instead of investing in pricey, high-end gear, organizations may achieve higher cost-efficiency by expanding horizontally by utilizing commodity hardware and distributed computing resources. Furthermore, distributed DBMS might lessen the demand for pricey data synchronization or replication procedures.
An appealing option for contemporary data-intensive applications and distributed computing settings, distributed DBMS offers better performance, scalability, availability, data locality, security, flexibility, and cost-effectiveness.
Disadvantages of Distributed DBMS:
These are a few of the main drawbacks of distributed DBMS:
- Distributed databases are intrinsically more complicated than centralized ones in terms of complexity. Data segmentation, replication, and synchronization techniques must be added as additional design considerations. A distributed system can be challenging to manage and coordinate, requiring specialized knowledge and abilities. The complexity of distributed DBMS might make mistakes more likely and make maintenance and troubleshooting more challenging.
- Distributed database management systems are very reliant on network connections between nodes. The functionality and dependability of the network infrastructure can considerably impact the effectiveness of the entire system. Network latency, bandwidth restrictions, and network outages might delay data updates and retrieval. The availability and responsiveness of the distributed DBMS may suffer if the network often suffers outages or bottlenecks.
- Maintaining data consistency in a dispersed setting is a complicated issue. Ensuring that all copies of the data stay consistent when duplicated across several nodes becomes difficult. Synchronization mechanisms must be in place to deal with updates, conflicts, and inconsistencies. While loose consistency models may bring data integrity problems, achieving great data consistency can lead to increased overhead and worse performance.
- Distributed DBMS can sometimes result in cost advantages but can also add to costs. A distributed infrastructure involves investments in network hardware, servers, and other resources to set up and maintain. The expenses of data replication, synchronization, and continuing network administration must be taken into account by organizations. Additionally, the complexity of distributed DBMS sometimes necessitates hiring specialized employees, which raises operations expenses.
- Distributed database management systems may provide additional security and privacy issues. Data security and protection grow increasingly challenging as data is dispersed across several nodes. According to organizations, data encryption, access control, and authentication procedures must be applied uniformly across all nodes. Furthermore, maintaining compliance with data privacy standards might take more work because data may cross many jurisdictions in a dispersed setting.
- A distributed DBMS may experience data inconsistencies as a result of network delay and concurrent updates. Conflicts may occur when updates spread among nodes, leading to inconsistent data states. The system becomes more sophisticated due to the careful management and coordination needed to resolve these conflicts and ensure data integrity.
- System performance overhead is higher for distributed DBMSs compared to centralized ones. Data replication, synchronization, partitioning, and coordination mechanisms use system resources and add overhead to communication and processing. This may affect how quickly the system responds and how well it performs overall, especially for complicated queries that call for gathering and combining data from numerous nodes.
Conclusion
Data distribution and replication, consistency, and replication, concurrent control, fault tolerance and recovery, distributed indexing and query processing, security and privacy, performance and scalability, data consistency in replicated databases, and data partitioning and placement are some subtopics distributed DBMS covers.
Researchers and experts in the sector are still looking into creative approaches to solve these problems. Distributed DBMS require constant improvements and adaptations, from designing effective data distribution and replication strategies to ensuring consistency across replicas, managing concurrency control, offering fault tolerance and recovery mechanisms, and addressing security and privacy concerns.
Distributed DBMS has the ability to revolutionize data management by solving the issues and maximizing the advantages, empowering businesses to successfully manage the complexity of contemporary data-intensive applications.