SPSS Kolmogorov-smirnov Analysis
Introduction
In insights, the Kolmogorov–Smirnov test (K–S test or KS test) is a nonparametric trial of the fairness of persistent , one-dimensional likelihood conveyances that can be utilized to contrast an example and a reference likelihood circulation (one-example K–S test), or to look at two examples (two-example K–S test). Basically, the test addresses the inquiry "What is the likelihood that this assortment of tests might have been drawn from that likelihood circulation?" or, in the subsequent case, "What is the likelihood that these two arrangements of tests were drawn from something very similar (however obscure) likelihood dispersion?". It is named after Andrey Kolmogorov and Nikolai Smirnov.
What is Kolmogorov- Smirnov measurement?
The Kolmogorov–Smirnov measurement evaluates a distance between the experimental dispersion capacity of the example and the total appropriation capacity of the reference circulation, or between the observational conveyance elements of two examples. The invalid dissemination of this measurement is determined under the invalid speculation that the example is drawn from the reference dispersion (in the one-example case) or that the examples are drawn from a similar circulation (in the two-example case). In the one-example case, the conveyance considered under the invalid speculation might be nonstop , absolutely discrete or blended . In the two-example case , the dispersion considered under the invalid speculation is a nonstop circulation however is generally unlimited. Nonetheless, the two example test can likewise be performed under more broad conditions that take into account intermittence, heterogeneity and reliance across tests.
SPSS - The Kolmogorov-Smirnov test
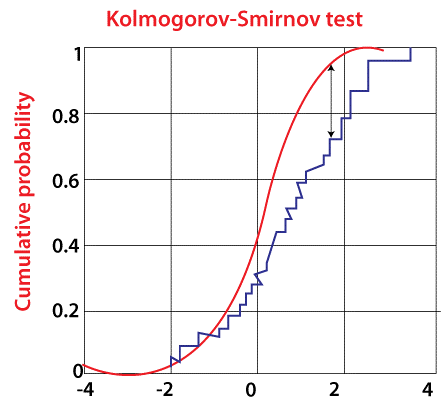
In SPSS, there's two important and popular methods for running the test:
- NPAR TESTS:Analyze NonparametricsTest Legacy Dialog one-Sample K-S... includes these test under them and is our strategy for decision since it makes well definite result.
- EXAMINE VARIABLES from Analyze Descriptive Statistics Explore is another option. This order runs both the the Shapiro-Wilk ordinariness test and Kolmogorov-Smirnov test.
Note that EXAMINE VARIABLES utilizes listwise avoidance of missing qualities of course. So, in the event that I test five factors, my five tests just use cases which don't have any sort of missing example cases on any of these five factors. This is generally not what you need but rather we'll tell the best way to keep away from this.
The two-example K–S test is one of the most helpful and general nonparametric techniques for contrasting two examples, as it is delicate to contrasts in both area and state of the exact aggregate conveyance elements of the two examples.
The Kolmogorov–Smirnov SPSS test can be altered or changed to fill in as an integrity of perfect test. In the exceptional instance of testing for ordinariness of the dispersion, tests are normalized and contrasted and a standard ordinary conveyance. This is comparable to setting the mean and fluctuation of the reference dispersion equivalent to the example assessments, and it is realized that utilizing these to characterize the particular reference appropriation changes the invalid conveyance of the test measurement (see Test with assessed boundaries). Different examinations have tracked down that, even in this remedied structure, the test is less incredible for testing ordinariness than the Shapiro–Wilk test or Anderson–Darling test. Nonetheless, these different tests have their own disservices. For example the Shapiro–Wilk test is known not to function admirably in examples with numerous indistinguishable qualities.
The Importance Kolmogorov-Smirnov test in real field
Numerous measurable tests and methodology depend on explicit distributional presumptions.
- The suspicion of ordinariness is especially normal in old style factual tests. Much unwavering quality displaying depends with the understanding that the information follow a Weibull dispersion.
- There are numerous non-parametric and powerful procedures that are not founded on solid distributional presumptions.
- We mean a strategy, by non-parametric, like the signature test, that did not depend on a particular distributional presumption.
- By strong, we mean a factual procedure that performs well under a wide scope of distributional presumptions.
- Be that as it may, procedures dependent on explicit distributional suspicions are overall more impressive than these non-parametric and hearty strategies.
- By power, we mean the capacity to recognize a distinction when that distinction really exists. Along these lines, in case the distributional suspicions can be affirmed, the parametric procedures are by and large liked.
- In case you are utilizing a strategy that makes an ordinariness (or another kind of distributional) presumption, affirm that this supposition that is indeed supported.
- Assuming that it is, the more remarkable parametric methods can be utilized. In the event that the distributional supposition that isn't defended, utilizing a non-parametric or strong strategy might be required.
- We produced 1,000 arbitrary numbers for typical, twofold remarkable, t with 3 levels of opportunity, and lognormal dispersions. The Kolmogorov-Smirnov SPSS test was executed, in all cases, to test for an ordinary appropriation.
Kolmogorov-Smirnov Test Parameters

The ordinary arbitrary numbers were put away in the variable F1, the twofold outstanding irregular numbers were put away in the variable F2, the t arbitrary numbers were put away in the variable F3, and the lognormal irregular numbers were put away in the variable F4.
Parameters explained:
Dn: the information are typically appropriated
Dabc: the information are not ordinarily circulated
F1 test measurement: D = 0.0241492
F2 test measurement: D = 0.0514086
F3 test measurement: D = 0.0611935
F4 test measurement: D = 0.5354889
Importance level: α = 0.05
Basic worth: 0.04301
Basic area: Reject F0 if D > 0.04301
True to form, the invalid theory isn't dismissed for the typically dispersed information, yet is dismissed for the excess three informational indexes that are not regularly appropriated.
The K-S Test few Limitations and Characteristics
An alluring element of K-S test is that the conveyance of the K-S SPSS test measurement doesn't rely upon the basic combined appropriation work was tried. Other benefit is that it is a definite test (and chi-square decency of-fit test relies upon a satisfactory example approximations size to be substantial). Regardless of these benefits, the K-S test has a few significant constraints:
- It just applies to persistent conveyances.
- It will in general be more delicate close to the focal point of the appropriation than at the tails.
- Perhaps the most genuine constraint is that the circulation should be completely determined. That is, if area, scale, and shape boundaries are assessed from the information, the basic locale of the K-S test is as of now not legitimate. With recreation it commonly should be controlled by.
A few integrity K-S SPSS tests, for example, the Cramer Von-Mises test and the Anderson-Darling test, are refinements constraints of the K-S test. As these refined tests are for the most part viewed as more remarkable than the first K-S test, numerous examiners incline toward them. Likewise, the benefit for the K-S trial of having the basic qualities be indpendendent of the fundamental conveyance isn't as a lot of a benefit as first shows up. This maybe be due to impediment 3 above (i.e., the appropriation boundaries are regularly not known and must be assessed from the information). So practically speaking, the basic qualities for the K-S test must be controlled by reenactment similarly concerning the Anderson-Darling and Cramer Von-Mises (and related) tests.
Outcome of the test concluded:
Note that albeit the K-S test is regularly evolved with regards to nonstop appropriations for uncensored and ungrouped information, the test has indeed been reached out to discrete dispersions and to controlled and gathered information. We don't talk about those cases here.
Further discussion on working with the test results
A direct execution of this test can be found in the Github vault. Working out the test measurement utilizing the observational total dissemination capacities is likely more or less convoluted for this. There are two renditions of the test measurement estimation in the code, the more straightforward adaptation being utilized to probabilistically check the more proficient execution.
Highlights:
- Non-parametricity and consensus are the extraordinary benefits of the Kolmogorov-Smirnov test yet these are adjusted by downsides in capacity to build up adequate proof to dismiss the invalid theory.
- Specifically, the Kolmogorov-Smirnov test is feeble in situations when the example observational combined circulation capacities don't digress unequivocally despite the fact that the examples are from various dispersions.
- For example, the Kolmogorov-Smirnov test is generally touchy to discrepency close to the middle of the examples in light of the fact that this is the place where contrasts in the chart are probably going to be enormous.
- It is less solid close to the tails in light of the fact that the total dispersion capacities will both be almost 0 or 1 and the distinction between them less articulated.
- Area and shape related situations that oblige the test measurement lessen the capacity of the Kolmogorov-Smirnov test to effectively dismiss the invalid speculation.
- The Chi-squared test is additionally utilized for testing whether tests are from a similar dissemination yet this is finished with a binning discretization of the information. The Kolmogorov-Smirnov test doesn't need this.