Parts of Compiler
What is a Compiler?
A compiler is a software tool that converts a high-level programming language code written by people into machine-readable commands that the computer can execute. It serves as an intermediary among the developer and the computer's hardware, converting source code from languages such as C, C++, Java, or Python into executable computer code that the computer's CPU is able to comprehend and execute.
The compilation process is divided into numerous steps, each of which plays a specialized function in translating source code to executable code. These steps are: lexical analysis, syntactic examination (interpreting), semantic analysis, intermediate code generation, code optimizing, code creation, and symbol table administration. Each process helps to ensure that the final program is valid, effective, and ideal for the intended hardware architecture.
Once the original source code has been built, the resultant executable file can be run several times without requiring recompilation, so long while the device being targeted and its operating system remain unchanged. This differs from interpreted languages, in which an interpreter executes the source code directly each time a program is run.
A translator is an application that transforms computer code from one programming language to another. Alternatively, we may argue that the compiler helps convert source code composed in a high-level programming language into computer code. To understand more about this topic, you might look at the differences between the compiler and a program that interprets code.
Parts of Compiler Layout
Every step in the compilation process alters the source program's depiction of the world. Every level of the compiler's stages gets input from the previous stage and feeds its output to the next stage.
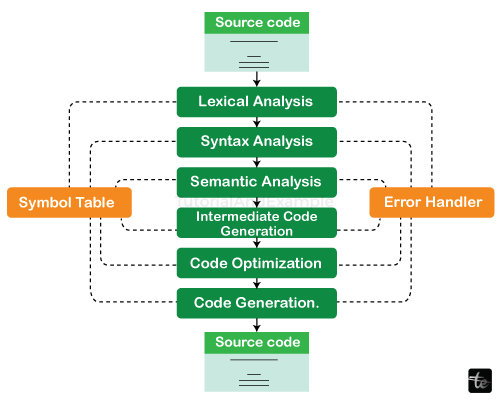
Each step in this procedure helps to translate fundamental concepts into computer code.
A compiler's stages are as follows:
- Lexical analysis
- Syntax analysis
- Semantic analysis
- Intermediate code generator.
- Code Optimizer
- Code Generator
Parts of the Compiler
All of these procedures change the source code by dividing it into tokens, creating parsing foliage, and performing various stages of source optimization of the code.
Part I: Lexical Analysis
Lexical analysis refers to the first stage of the compiler's source code search process. Tokens may be manufactured by following this technique from left to right, letter by word.
By recognizing the tokens, the source program's character stream is organized into meaningful sequences. It enters the matched tickets in a symbol table and proceeds to the next Part using that token.
The key roles for this Part include:
- Recognize word components in source code.
- After sorting lexical units into groupings such as reserved words and constants, assign them to different tables. It will disregard any comments written in the underlying code.
- Determine which tokens are not linguistically suitable.
Example of lexical analysis:
x = y + 10
Part II: Syntax Analysis
The primary purpose of syntax examination is to recognize a group in code. It determines whether a text follows the chosen style or not. The major purpose of this step is to verify whether or not the developer provided accurate source code.
The syntax analysis relies on rules specific to the computer language being used by building the parse tree using tokens. It also defines the language's grammar or syntax, as well as the structure of the original tongue.
Here's an overview of the responsibilities performed during this Part.
- Consider the lexical analyzer's symbols.
- Assesses the expression's syntactic accuracy.
- Send in any grammatical errors.
- Construct a parsing tree, which is a hierarchical organization.
- Syntax Analysis: Any identifier or integer is an expression.
- If x is an identity & y+10 is an equation, then x= y+10 represents a statement.
Consider the parse tree in the following example:
(a+b)*c
In Parse Tree
- Interior node: record containing a function field and a file for the children.
- Leaf records include two or more fields, one for the token and another for further information on the token.
- Ensure that the program's components fit together meaningfully.
- Collects type information and tests for type compatibility.
- The source language permits check operands.
Part III: Semantic Analysis
Semantic analysis examines the code's semantic coherence. It tests the semantic compatibility of the submitted source code with the symbol the table, syntax tree generated in the previous step, or both. It also affects whether the coding conveys the intended message.
Semantic Analyzer will look for methods that are called with incorrect parameters, undeclared variables, type mismatches, incompatible operands, and other issues.
During the semantic analysis stage, the following responsibilities are performed:
- Supports you in storing type data in a symbol-based table or syntactic tree.
- Allows you to type-check.
- When there is a type incompatibility and no exact type rectification rules that match the required operation is accessible, a semantic error appears.
- Collects type data and ensures type compliance.
- Checks if the operands are permitted in the native language.
Example of semantic analysis:
Float x = 20.2; float y = x*30; the semantic analyzer converts integer 30 to float 30.0 before multiplication.
Part IV: Intermediate Code Generation
The compiler generates intermediate code on the intended machine when the semantic analysis stage is completed. It refers to a piece of software for a hypothetical computer.
Intermediate code exists in between the highest level and machine-level languages. It is vital to write this extra code in a form that makes it easy to convert into the machine being targeted instructions.
Uses of Intermediate Code Generation:
- It should be derived from the original program's semantic representation.
- Contains the numbers calculated throughout the translating process and assists in the target language adaptation of the intermediary code.
- Permits you to maintain the source language's priority hierarchy intact.
- It has the right number of instruction operands.
- Instance of Intermediate Code Generation.
Total = Count + Rate * 5
The address code technique is used to produce intermediate code.
t1 = int_to_float(5).
T2 = rate * t1 t3 = count + t2 total = t3.
Part V: Code Optimization.
The next level is code optimization, sometimes known as intermediate code. This stage eliminates unnecessary code lines and rearranges the sequence of statements to speed up the program's performance while conserving resources. The major goal of this step is to enhance the intermediate code so that it runs faster and occupies less space.
The key duties for this Part are as follows:
- It supports you in deciding between efficiency and compilation speed trade-offs.
- This method extends the target program's runtime and simplifies code creation while retaining intermediate representation.
- Eliminating unnecessary variables and inaccessible code
- Remove non-changed items from the loop.
Example of code optimization:
a = into float (10).
b = c * a, d = e + b, and f = d.
Can become:
b = c * 10.0, f = e + b.
Part VI: Code Generation
The final and ultimate Part in the compiler process is code generation. The web page code and object's code is generated using inputs from the code optimization steps. The aims of this step are to allocate storage and produce relocatable computer code.
It also enables for varied memory spaces. The intermediate code directives are converted into machine instructions. This Part converts the optimizer or code in between into the target language.
Machine language is the desired vernacular. As a consequence, at this step, all memory areas and registers are selected and allocated. This step generates the code that is subsequently executed to get inputs and output the intended outcomes.
Example of code generation:
a = b + 60.0
It might perhaps be translated into registers.
MOVF a, R1; MULF #60.0, R2; ADDF R1, R2.
Symbol Table Management
Each identifier's entry within a symbol tables has fields for its characteristics. This component allows the compiler to analyze the identifier record with more ease and speed. Additionally, a symbol table assists with scope management. Both the symbol tables and exception handler interact with all stages and update the symbol table as needed.
- Linear analysis involves reading the text stream form left to right throughout the scanning process. It is then broken into many tokens with greater meanings.
- Hierarchical Analysis - During this phase of analysis, tokens are classified hierarchically onto nested groups depending on their collective meaning.
- Semantic Analysis - This step determines if each part of the initial program is relevant or not.
- The compiler comprises two modules: the front side and its back end. Front-end comprises the Lexical analyzer, semantics analyzer, syntax analyzer, and code intermediate generator. And the remainder are put together to form the rear end.
It stores:
- It stores both strings and literal variables.
- It supports the saving of function IDs.
- Furthermore, it prefers storing variable and variable names.
- Labels from the original languages are stored there.
Error Handling Routine
In the compiler's design process, errors may arise in all of the following parts:
- Lexical analyzer: incorrectly worded tokens
- Syntax analyzer: Missing parenthesis
- Intermediate code generator: Mismatched operands in an operator
- Code Optimizer: Whenever the statement is unreachable
- Code Generator: When memory is full or appropriate registers are not allocated.
- Symbol tables: Error with numerous declared IDs
The most common problems are wrong token sequences during type, invalid sequences of characters in imaging, scope errors, and parser errors in the analysis of semantics.
Any of the aforementioned parts may encounter the issue. To restart the compilation process, the Part must resolve any mistakes that it detects. To finish the compilation procedure, these problems must be sent to the error handler. In most circumstances, notifications are used to convey errors.
Advantages of Compiler Phases
The process of assembling is separated into phases, each of which has its own set of chores and advantages. These steps improve the compiler's overall efficiency, correctness, and management. Here are some benefits of having separate stages in a compiler.
- Modularity and simple development: By breaking down the creation process into steps, developers may focus on specific responsibilities at each level. The modular design simplifies compiler development and maintenance by allowing various specialists to work on different phases.
- Efficiency: Dividing the gathering process into phases enables for optimizations tailored to each phase. This implies that each step may prioritize its own set of adjustments, resulting in an improved overall compilation process.
- Parallelism: Separate stages can be conducted concurrently, particularly on contemporary multi-core CPUs. Parallelism accelerates up the compilation procedure by allowing separate phases to operate on different areas of the source code at the same time.
- Error Separation: By isolated mistakes to certain stages, it is easier to find and troubleshoot problems in the code. If an error happens during a particular phase, it is more probable that the underlying reason is connected to that phase.
- Language autonomy: The early stages of the the compiler, including lexical evaluation and parsing, are concerned with the grammar of the language. By isolating these steps, the rest of the translator can concentrate on converting the syntax trees into client software, making the compiler more adaptable to diverse programming languages.
- Separate optimization stages might concentrate on various areas of code enhancement, such as constant folds, loop optimization, and registration allocation. This enables an additional targeted and efficient optimization procedure.
- Portability: By separating steps, the compiler may be more easily ported to multiple systems or architectures. As long as the the front-end (early stages) can handle the target language's grammar, the server side (later phases) may be configured to create code for other architectures.
- Flexibility: If you wish to update or improve a certain component of the compilation, you may focus on that step without impacting the overall compilation process.
- Incremental Compilation: Certain compilers offer incremental compilation, which means that just the updated code is recompiled. This functionality is enabled by the modular architecture of stages, which makes it easy to detect which sections of the compilation require updating.
- Optimization Levels: Compilers frequently provide many optimization levels that balance compilation time against code performance. The flexible nature of phases enables you to apply a variety of optimizations based on the intended trade-off.
Conclusion
Every stage of the compiler's operation changes the source code from one format to another.
There are six steps to compiler design:
1) Lexical analysis.
2) Grammar test
3) Cognitive assessment
4) A mid-level code creator
5) Code Generator Number
6) Code Maker.
When a compiler examines source code, the lexical analysis stage comes first. The primary purpose of syntactic analysis is to determine textual arrangement. Semantic analysis looks at the code's semantic coherence. After completing the semantic analysis process, use the compiler to generate additional code for the intended machine. During the source code optimization process, redundant code lines are deleted and the sequence of statements is reorganized. The step of code production creates page or object code using data from the code optimization Part. A symbol table has an entry for each symbol identifier and fields for the identifier's characteristics. Error handling procedure handles errors and reports at numerous stages.