Overfitting and Underfitting in Machine Learning
We actually talk about prediction errors, which are a measure of a machine learning model's performance and accuracy. Think about the possibility that we are developing a machine learning model. A model is considered effective machine learning software if it generalises any new input data from the problem domain in a suitable way. Because of this, we are able to predict future data that the data model has never seen. Assume for a moment that we wish to assess how well our machine learning model can incorporate and adapt to new input. Overfitting and underfitting are the main causes of the poor performance of machine learning methods for this.
Let's first define two key words before moving forward:
Bias
Assumptions, a model makes to create a function simpler to understand. Actually, it is the training data's error rate. When the error margin is large, we refer to it as high bias, and when it is low, we refer to it as low bias.
Variance
The variance is the distinction between the error rate of the training and testing sets of data. When the difference between the mistakes is low, the variance is said to be low, and when the variation is great, it is said to be high. Typically, we wish to generalise our model with a minimal variance.
Overfitting
When a statistical model fails to produce reliable predictions on test data, it is said to be overfitted. A model begins to learn from the noise and erroneous data elements in our data set when it is trained with such a large amount of data. And when using test data for testing yields high variance. Due to too many details and noise, the model fails to appropriately identify the data. The non-parametric and non-linear approaches are the root causes of overfitting since these types of machine learning programs have more latitude in how they develop the model based on the dataset, making it possible for them to produce highly irrational models. If we have linear data, employing a linear algorithm is one way to prevent overfitting; if we are applying decision trees, utilising variables like the maximal depth is another.
In general, overfitting occurs when machine learning algorithms are evaluated differently for training data and unknown data.
Overfitting has the following causes:
- Both volatility and bias are high
- The model is very intricate
- The quantity of training data
Examples:
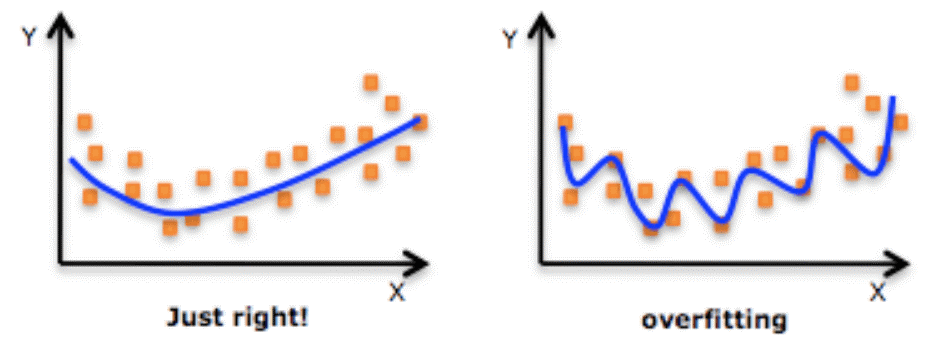
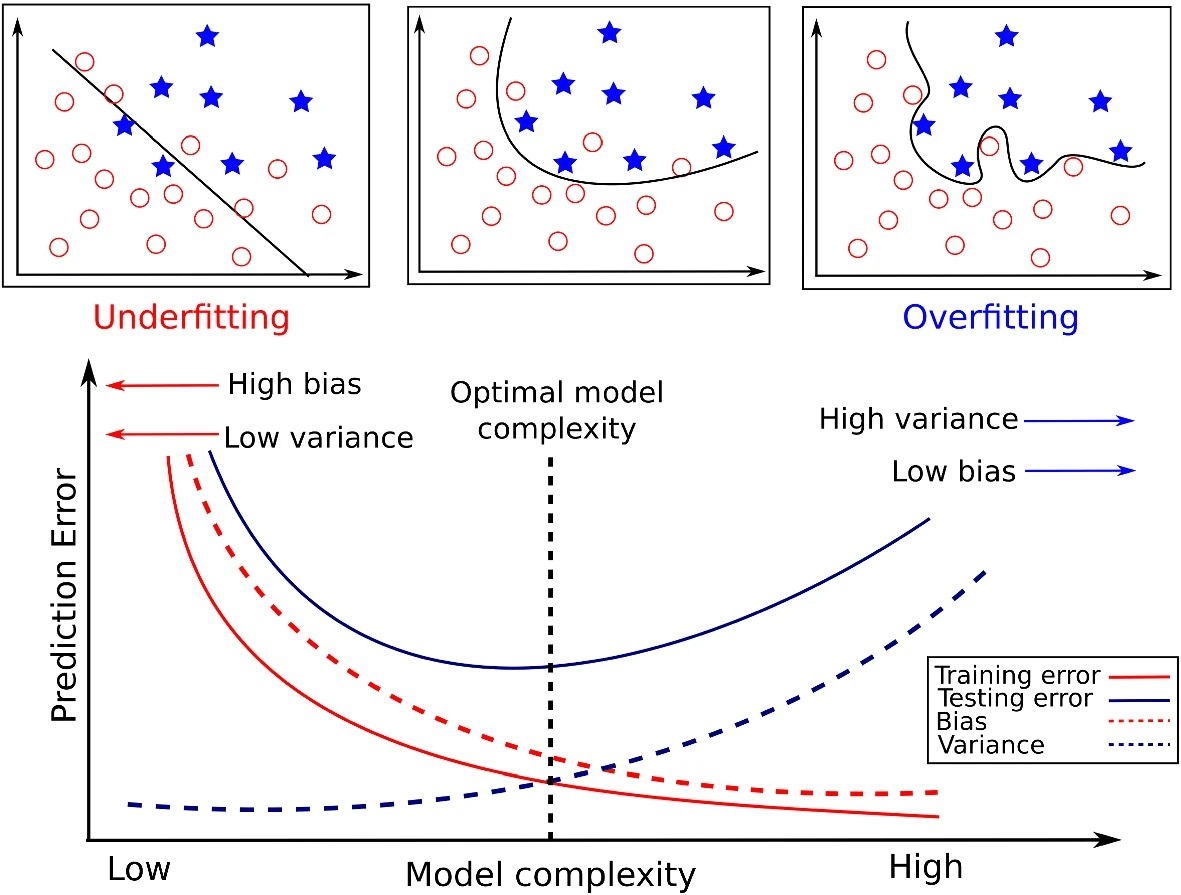
Methods to lessen overfitting
- Expand the training data.
- Simplify the model.
- During the training phase, an early stop is made (Keep an eye on the loss during the training time, and cease exercising as soon as it starts to rise).
- Regularization of the Ridge and the Lasso
- To combat overfitting in neural networks, use dropout.
Good Fit in a Statistical Model
It is optimal to establish a good fit on the data when the model produces predictions with zero error. At a point between overfitting and underfitting, this condition is possible. It will be necessary to examine how well our model performs over time as it learns from the training sample in order to comprehend it.
Our model will continue to learn as time goes on, which will result in a continual decline in the model's error on training and testing data. Due to the existence of noise and less valuable features, if the model is allowed to learn for an excessively long time, it will be more susceptible to overfitting. As a result, our model's performance will decline. We will halt just before the mistake begins to increase in order to get a satisfactory match. As of right now, the model is stated to perform well both on training datasets and on our fictitious testing dataset.