Extract Specific Text from PDF Python
Introduction
Portable Document Format (PDF) files are frequently utilized for sharing documents electronically. PDF files are used for information sharing by both individuals and companies. To process PDF files further, we frequently need to extract specific data. But it could be challenging to extract text from a PDF file, especially if the layout and style are complex. We have many methods to solve this issue.
Here, we'll outline the approach Python users use most frequently to extract text from PDF files. Python comes with several libraries that make effective PDF text extraction possible.
Python Libraries for PDF Processing
Python comes with a number of well-integrated libraries which are capable of handling unstructured data formats like PDF files. Let us see some of the Python libraries for processing PDFs.
- PyPDF2: The pages of a PDF file can be split, combined, cropped, and modified using this Python library for PDF files. Using PyPDF2, text may be taken out of PDF files.
- PDFQuery: It is a Python library for PDF processing. It aims at correctly obtaining data from sets of PDFs using the least amount of code.
- PyMuPDF: For the MuPDF C library, PyMuPDF is a Python wrapper. It enables Python programmers to open, edit, and modify PDF files. In addition, PyMuPDF allows you to extract text and images from PDF files, access the documents' metadata, and decrypt encrypted PDF files.
- ReportLab: It is a free and open-source Python library that can be employed to create and edit PDF documents. With capabilities for adding fonts and graphics, it offers a high-level API for building PDF documents from scratch.
- Pdf2dox: Data can be extracted from PDF files using this Python library with the PyMuPDF module.
Setting up the Development Environment
It is crucial to set up a working environment and install the necessary Python libraries before reviewing the text extraction processes from PDF.
- Install Python: If it still needs to be, it must be installed on your system.
- Install pip: To check if pip is installed, use the following command in Python.
py -m ensurepip --default-pip
Install or upgrade pip by downloading it and running the following code if it cannot run automatically.
pip.python get-pip.py
- Install the required library: PDF files are compatible with any Python library. Here, we'll set up PyPDF2, a widely used library. Install it by executing the below command.
pip install PyPDF2
Your development environment is ready when you install Python and the necessary libraries. The IDEs Visual Studio Code, PyCharm, and Sublime Text are just a few examples of text editors you can use to write Python code.
Step-by-Step Process of Extracting Text from PDF Using PyPDF2 in Python
To extract files, we'll make use of the PyPDF2 Python library.
Input PDF Python Program
from PyPDF2 import PdfReader
read = PdfReader('report1.pdf')
print(len(read.pages))
page = read.pages[0]
text = page.extract_text()
print(text)
Let's now examine each code in detail.
- read = PdfReader('simple.pdf')
An object of the PDFReader class was generated using the PyPDF2 package. The path to the PDF file's positional parameter, which is necessary, will be provided.
- print(len(read.pages))
A List of PageObjects can be found in the pages property. To know the number of pages in the pdf file, we can use the built-in len() Python method.
- page = read.pages[0]
We may also access a particular PDF file page using the page index. With this command, we will receive the file's first page since Python lists begin indexing at 0.
- text = page.extract_text()
The above command is employed to extract text from the PDF page.
- print(text)
This command is used to display the text.
Output
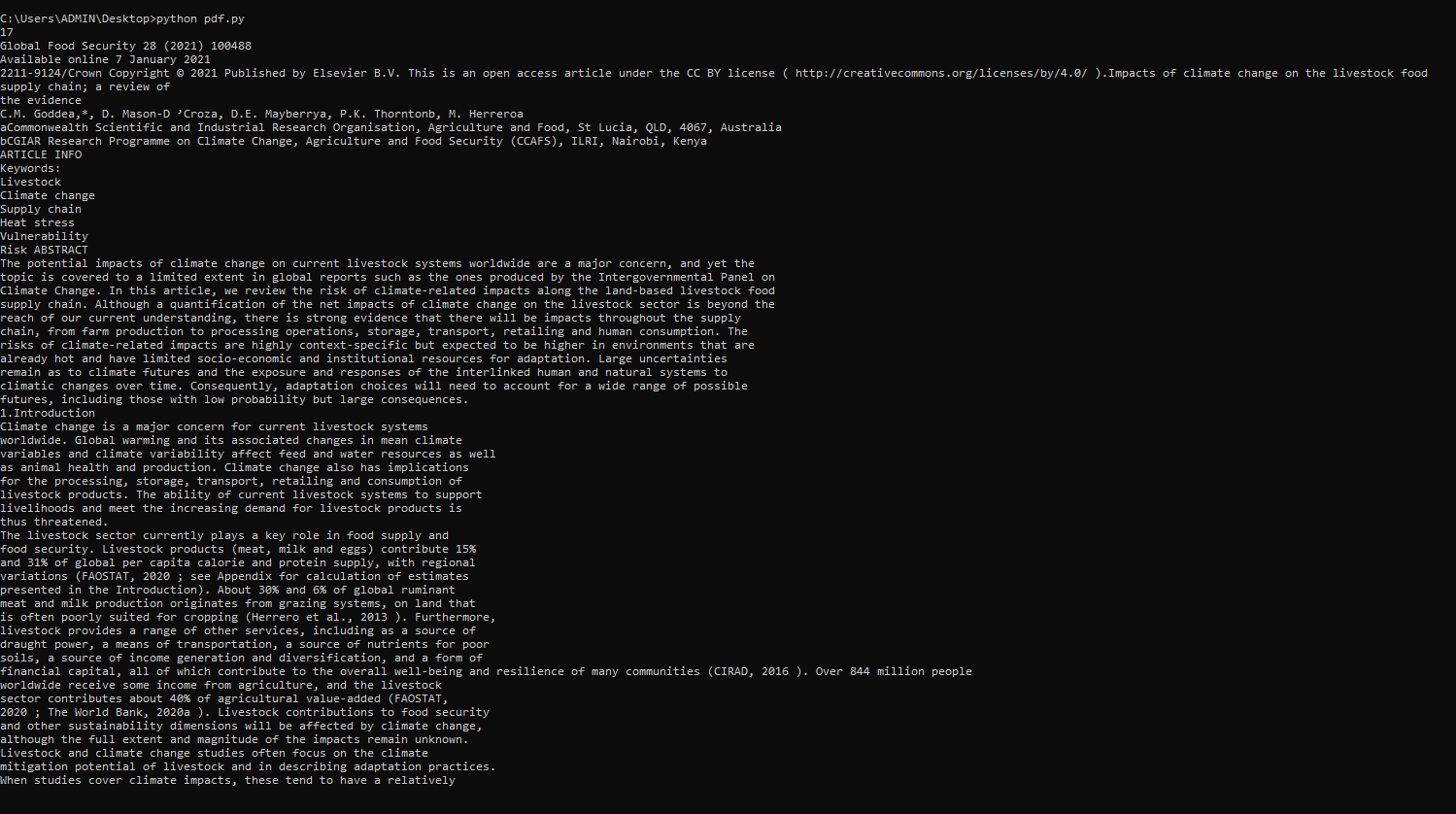
Pre-processing extracted text
Several pre-processing methods, such as deleting stopwords, lowercasing, removing punctuation, stemming, or lemmatization, are used to clean and normalise the obtained text in Python.
Code
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
nltk.download('punkt')
nltk.download('stopwords')
text = "Extracting specific text from a pdf in python."
tokn = word_tokenize(text)
end_w = set(stopwords.words('English'))
filtered_txt = [x for x in tokn if not x.lower() in end_w]
clean_t = [x.lower() for x in filtered_txt if x.isalpha()]
print(clean_t)
Output
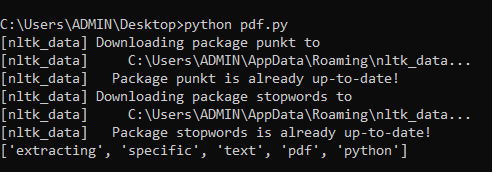
Stop words such as "is," "a," "for," "and," "it," and "has" have been eliminated in this phase, and all the text's words have also been lowercase.
Extracting text from PDF using PDFQuery
How to Use PDFQuery
The Python library PDFQuery provides a straightforward approach for extracting data from PDF files using CSS-like selectors to locate things in the PDF file.
The necessary data is then accessed by its specific position within PDF file after the PDF file has been read as an object and converted to an XML file.
Let's consider an example to demonstrate how it functions.
from pdfquery import PDFQuery
pdf = PDFQuery('refort.pdf')
pdf.load()
text_elements = pdf.pq('LTTextLineHorizontal')
text = [ch.text for ch in text_elements]
print(text)
In the above code, we first create a PDFQuery object by providing the filename of the PDF file from which we wish to extract data. Then, by using the load() method, we load the page into the object.
The text components in the PDF document are then located using CSS-like selectors. To find the elements, the pq() function is utilized. This method gives back a PyQuery object which symbolizes the selected components.
At last, after extracting the information from every element's text attribute, we save it in a list called text.
Output

Let's think about another way to read PDF files, extract some data items, and utilize PDFQuery to create a structured dataset. The steps that we'll take are as follows:
- Package installation.
- Import the libraries.
- Read and convert the PDF files.
- Access and extract the Data.
Package installation
To perform any analysis and exhibit the data, we must first install PDFQuery and Pandas.
pip install pdfquery
pip install pandas
Import the libraries
We import the below two libraries to extract text from PDF
import pandas as pd
import pdfquery
Read and convert the PDF files
pdf = pdfquery.PDFQuery('customers.pdf')
pdf.load()
pdf.tree.write('customers.xml', pretty_print = True)
pdf
We'll load the pdf file and read it as an element object. The pdf object is converted into an Extensible Markup Language (XML) file. This file includes the information and metadata for a specific PDF page.
The XML defines a set of rules for encoding PDF which is comprehensible to both people and machines. Locating the data we are interested in obtaining from the XML file can be done with the use of a text editor.
Access and extract the Data
The LTTextBoxHorizontal tag contains the data we are attempting to extract, and we can also view the metadata that goes along with it.
The text box's Left, Bottom, Right, and Top coordinates are indicated by the values [68.1, 231.57, 101.990, and 234.893] in the XML fragment. These give the boundaries surrounding the data we need to obtain.
With the text box's coordinates as a guide, let's access and extract the student's name.
customer_name = pdf.pq('LTTextLineHorizontal:in_bbox("68.1, 231.57, 101.990, 234.893")').text()
print(customer_name)
Output
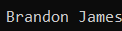
These are the steps to extract text from PDF files using PDFQuery.
There may be problems if the data we wish to extract is sometimes in different places in every file. Fortunately, PDFQuery also allows you to query tags that contain a particular string.
Extract text from a PDF file using the PyMuPDF library.
File formats, including XPS, PDF, CBR, and CBZ, are supported by the Python library PyMuPDF.
Installation
pip install PyMuPDF==1.21.0
The below steps need to be followed to extract the text from the pdf files:
- Importing the library
- Opening document
- Extracting text
1. Importing the library
import fitz
2. Opening document
doc = fitz.open('report.pdf')
Here, the filename should be a Python string, and we generated an object called "doc."
3. Extracting text
for pg in doc:
text = pg.get_text()
print(text)
The get_text() method was employed to iteratively retrieve the text from each page of the pdf file.
Output
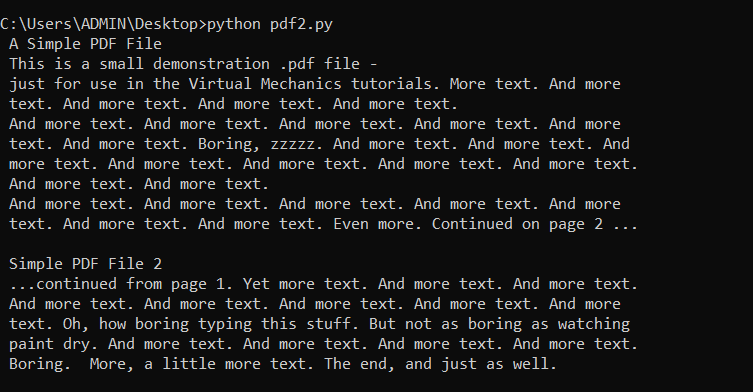
Using the above steps, one can extract text from pdf using the PyMuPDF library.
Conclusion
We have seen how PyMuPDF and Python assist us with text extraction. One can use this technique instead of manually copying individual text lines or utilizing a PDF reader. Hundreds of documents can be automatically extracted and arranged hierarchically.
Due to the widespread usage of PDF files for document storage and distribution, data extraction from such files is a crucial task.
We have used PyPDF2, PyMuPDF, and PDFQuery, to extract text from a PDF file.
For extracting data from PDFs, the Python library PDFQuery is an effective tool. PDFQuery is a good alternative for anyone wishing to extract data from PDF files because of its simple syntax and thorough documentation. Additionally, it is open-source and adaptable to many use cases.
Data extraction from PDF files is extremely simple with the PYPDF2 library. Additionally, we are aware that there is a massive amount of unstructured data included in pdf formats, and after extracting the texts, we can do a variety of analyses and locate the internal information in accordance with your business needs.