Agglomerative Clustering with and without Structure in Scikit-Learn
Agglomerative Clustering with and without Structure in Scikit-Learn
In this world of enhancing technology, every media and technology is running on algorithms, and among those algorithms, the hierarchical clustering algorithm is quite popular and significantly used these days.
In this tutorial, we will discuss agglomerative clustering. The agglomerative clustering is basically the hierarchical clustering algorithm that is used to arrange the same type of data points into clusters. This approach is actually the bottom-up approach that starts when we treat every data point as a single cluster and merge the closest pair of the cluster before all the data points are assembled together into the sing cluster or into the pre-defined number of clusters. Through this article, we will discuss how we can perform agglomerative clustering in Sci-kit Learn, which is one of the most popular machine learning libraries that are used in Python. Here we will cover the differences between agglomerative clustering with structure and agglomerative clustering without structure. Before explaining things in detail or elaborating on the basics of agglomerative clustering in sci-kit learn, firstly, let us discuss the basics of hierarchical clustering and understand how it works.
What do we mean by Hierarchical Clustering?
Hierarchical clustering is a kind of clustering algorithm which is used to assemble the corresponding data points into clusters. This is a bottom-up approach that basically starts when we treat is data point as the lone cluster and then merge the closest combination of clusters before all the data points are assembled into the lone cluster, or we can say that the pre-defined number of clusters.
Hierarchical clustering is divided into two parts:
- Agglomerative Clustering
- Divisive Clustering.
Agglomerative clustering is basically the bottom-up approach that actually starts when we treat various data point as lone cluster and then combines the closest set of clusters before all the data points are assembled into a lone cluster or a rooted number of clusters.
Divisive clustering is the top-down approach that starts by serving all the data points as the lone cluster and then breaks the cluster into smaller clusters before every cluster contains only one data point.
How does Hierarchical Clustering actually work?
Hierarchical clustering algorithm is basically a replicated algorithm that starts by serving every data point as a lone cluster. In each replication, the algorithm acknowledges the set of clusters that are closest to each other and then combines them into the lone cluster. This process will continue before all the data points are assembled into a lone cluster or a destined number of clusters.
The algorithm also uses the distance metric just to check the common thing in between the data points and also to check the closest set of clusters. There are Some common distance metrics that are used in hierarchical clustering, and they are: Euclidean distance, Manhattan distance, and cosine similarity.
Finally, when all the data points are assembled into clusters then, the algorithm will create the dendrogram that will show the hierarchical structure of the clusters. A dendrogram is basically a tree-like diagram that shows the order of cluster combination and the distance at which the clusters are completely combined.
How to perform the Hierarchical Clustering in the Scikit-Learn?
As we all know that in Python programming, the Scikit-Learn is one of the most popular machine-learning libraries which is used for Python, and it provides a broad range of clustering algorithms which, includes hierarchical clustering as well. Well, in this section, we will be going to discuss how we can perform hierarchical clustering in the Scikit-Learn by using the Agglomerative Clustering class.
To demonstrate the hierarchical clustering in the Scikit-Learn, firstly, we need to import the Agglomerative Clustering class from the sklearn.cluster module itself.
Here we can see the code to import the Agglomerative Clustering class:
Importing the Agglomerative Clustering class
from sklearn.cluster import AgglomerativeClustering
Finally, when we have imported the Agglomerative Clustering class, we can be able to create the instance of the class by just specifying the actual number of the clusters and the actual distance metric which we want to use. The Agglomerative Clustering class basically provides various distance metrics that one can use to check the common terms in between the data points and which are Euclidean, manhattan, and cosine.
Here we can see the code through which we can create an instance of the agglomerative class:
Creating the instance of the Agglomerative Clustering class
clustering = AgglomerativeClustering(n_clusters=3,
affinity="Euclidean")
When we finally create the instance of the Agglomerative Clustering class, then we are able to fit the model by just calling the fit() method of the clustering object. This method actually takes the data as the input parameter and then returns the cluster level for every data point.
Now let us see the code that fits the hierarchical clustering model to the data:
clustering.fit(data)
After the model is fitted to the data, we are able to use the labels_attribute of the clustering object to get the desired cluster label for each data point. Then the label attribute will return an array of integers that will represent the cluster labels for each data point.
Here below, we can find the code to get that cluster label for every data point:
Getting the cluster labels for every data point
labels = clustering.labels_
The absolute algorithm is the agglomerative Clustering algorithm that basically uses the highest or full linkage method to combine the clusters. This highest or full link method is actually the distance-based method that computes the distance between the extreme points in the clusters.
Now if we talk about the ward algorithm, then it is quite useful, and here when the data points have a clear structure in such a way that when the data points from the clusters which are having a circular or spherical shape. The complete algorithm is quite useful when the data points do not have any clear structure and the clusters are more irregular or in a prolonged shape. Here in the down below, we are able to see an example which is illustrating the basic difference between the ward and the complete algorithms.
Importing the necessary modules
from sklearn.datasets import make_circles
from sklearn.cluster import AgglomerativeClustering
Generating the data
data, _ = make_circles(n_samples=1000,
noise=0.05,
random_state=0)
Thereafter we have used the Agglomerative Clustering class, which performs the hierarchical clustering on the data by using the ward and complete algorithm. Here we have created two instances of the Agglomerative clustering class in which; one was for the ward algorithm, and the other was for the complete algorithm.
Here below, we can be able to see the code that basically performs the hierarchical clustering on the desired date by using the ward and the complete algorithms:
Creating an instance of the AgglomerativeClustering class for the ward algorithm
ward = AgglomerativeClustering(n_clusters=2,
affinity="Euclidean",
linkage="ward")
Now Fitting the ward algorithm to the data
ward.fit(data)
Creating an instance of the AgglomerativeClustering class for the complete algorithm.
complete = AgglomerativeClustering(n_clusters=2,
affinity="euclidean",
linkage="complete")
Fitting the complete algorithm to the data
complete.fit(data)
Finally, when the ward and the complete algorithms are fitted to the data, the user can use the label attribute of the word and the complete objects to get the cluster levels for every single data point. Here is the code below that helps in getting the cluster labels for every data point using the ward and the complete algorithm.
Getting the cluster labels for every data point by using the ward algorithm
ward_labels = ward.labels_
Getting the cluster labels for every data point by using the complete algorithm
complete labels = complete.labels_
Thereafter we can plot the data points and the cluster levels to examine the results of the ward and the complete algorithms. Here we can see the code which plots the data point and the cluster label by using the ward and complete algorithms:
Importing the pyplot module
import matplotlib.pyplot as plt
Plotting the data points and the cluster label by just using the ward algorithm
plt.scatter(data[:, 0], data[:, 1],
c=ward_labels, cmap="Paired")
plt.title("Ward")
plt.show()
Plotting the data points and the cluster labels by using the complete algorithm
plt.scatter(data[:, 0], data[:, 1],
c=complete_labels, cmap="Paired")
plt.title("Complete")
plt.show()
Output
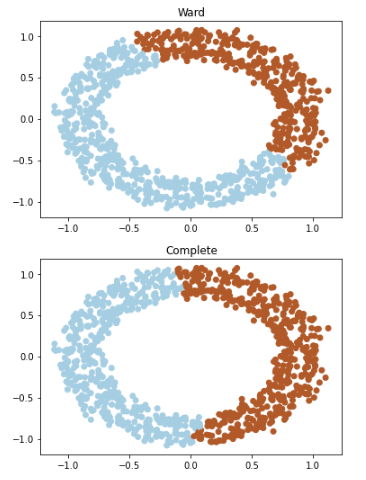
Clusters are formed using Agglomerative Clustering.
In the output, we are able to see that the plot is generated by the ward algorithm showing that all got them successfully identified the circular cluster in the given data. And similarly, the plot generated by the complete algorithm shows that the algorithm is lagging in identifying the circular cluster, and alternately, it assembles the data points into the two elongated clusters.
In simple words, hierarchical clustering is a type of clustering algorithm that is used to assemble similar kinds of data points into clusters. This clustering is a bottom-up approach that starts by treating each data point as a single cluster and then combines the closest set of clusters before all the data points are assembled into a lone cluster, or, we can say, the destined number of clusters.
Scikit-learn is one of the most popular machine learning libraries for Python, and it provides the white range of clustering algorithms which includes hierarchical clustering. The Agglomerative clustering class in the library provides two algorithms for hierarchical clusters, and those are the ward and complete. Well, the Ward algorithm is just an agglomerative clustering algorithm that uses Ward’s method to combine the clusters and is quite useful for data by having a clear structure. The complete algorithm is basically the agglomerative clustering algorithm which uses the maximum or the complete linkage method to combine the clusters and is also quite useful for data without a clear structure.
What are the differences between Hierarchical Clustering with and without structure?
Hierarchical clustering is performed with or without the structure. In hierarchical clustering, which is structureless, here, the algorithm treats every data point as independent, and the distance between the data points is calculated using a distance metric. In hierarchical clustering, with is having a structure, the algorithm examines the structure of the data, and then it uses the connectivity matrix to check the distance between the data points.
There are various differences between hierarchical clustering with and without the structure:
- In hierarchical clustering, which doesn't have a structure, here, the distance between the data points is calculated by using the distance metric. In hierarchical clustering, which has a structure, here, the distance between the data points is examined by the connectivity matrix.
- In hierarchical clustering, which is without a structure, the clusters are made, and it is based on the distance between the data points. In hierarchical clustering with a structure, the clusters are made based on the connectivity between the data points.
- In hierarchical clustering having no structure, the algorithm does not produce superb results for the data with a non-linear structure. In hierarchical clustering, which has a structure, the algorithm can produce more and more accurate results for having a non-linear structure.
- And lastly, In hierarchical clustering, which doesn't have a structure, the algorithm produces clusters having uneven sizes. In hierarchical clustering with the structure, the algorithm can generate clusters having more uniform sizes.
Conclusion
In this tutorial, we have elaborated the hierarchical clustering and understood how one could perform agglomerative clustering in Scikit-Learn. Here we have also explained the basic differences between hierarchical clustering having a structure and without having a structure.
Hierarchical clustering is a powerful clustering algorithm that is commonly used in machine learning and data mining. A bottom-up approach starts by treating each data point as a single cluster and then combining the closest set of clusters before all the data points are assembled into a lone cluster or a destined number of clusters. Here we explained Scikit-Learn, which is a popular machine-learning library for Python, and it provides a versatile range of clustering algorithms which includes hierarchical clustering. The AgglomerativevClustering class in the Scikit-Learn helps us to carry out hierarchical clustering with or without having a structure.
Hierarchical clustering having a structure can be able to produce more feasible results for the data with having some non-linear structures and can able to produce clusters with more uniform sizes. It is quite important to know about the differences between hierarchical clustering with a structure and without a structure and to choose the appropriate approach, which is based on the characteristics of the data.