Java Program to Determine the Unicode Code Point at Given Index in Strin
The English alphabet can be converted to numbers using the ASCII code, which also allows numbers to be converted into an assembly language that computers can understand. Each character has been given a number between 0 and 127 for that reason. Case matters when it comes to alphabets; lowercase and uppercase are handled differently. It is not necessary to list all of the ASCII values in a table; instead, it is preferable to use the table in the picture below.
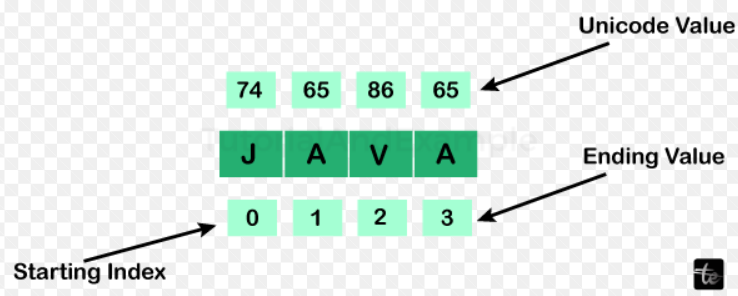
The full ASCII values table can be interpreted. The following are the extremities assigned so that, by memorization of the entire table, one can accurately estimate the Unicode value. All Unicode alphabets, including uppercase and lowercase, can be extracted using this table.
| S.No | Cases that have to be followed and remembered | Unicode Value |
| 1 | Alphabetical starting letters in uppercase | 65 |
| 2 | Alphabetical ending letters in uppercase | 90 |
| 3 | Alphabetical starting letters in lowercase | 97 |
| 4 | Alphabetical ending letters in lowercase | 122 |
This enables us to obtain the Unicode of other values, such as B, which is 66. The preceding table illustrates that the uppercase starting value is A, which starts with 65, and for B, we can increment by 1. The values for 'b' and 'j' are 98 and 106, respectively. In the same way, 'J' is Unicode74, 'N' is Unicode78, 'K' is Unicode75, and so on.
codePointAt() : The built-in codePointAt() function is used when a user wants to return a character at a specified index. The index, which goes from 0 to length()-1, relates to character values (Unicode units). This built-in function returns the Unicode point (character) at the given index. Character values (Unicode units) are referred to by the index, which has a range of 0 to length()-1.
Syntax:
java.lang.String.codePointAt();
- The character values' index is the parameter that has to be taken.
Returns:
The Unicode value at the given index is returned by this method. The index, which goes from 0 to [length()-1], corresponds to char values, or Unicode code units. The character at the index's code point value is stored simply.
Exception:
Taking into consideration the idea of exceptions in this context, an exception is only a runtime issue that interferes with the program's usual operation. Currently addressing the function's exception. An exception is occasionally raised when an index that is out of memory is attempted to be accessed. The conceptual data on the codePointAt() method's exceptions is provided below. Likewise, talking about the drawbacks of the IndexOutOfbound exception and the try-catch method for handling it.
There are mainly three cases for implementing the Unicode codePointAt().
- Java Character codePointAt(char[] arr, int i) method
- Java Character codePointAt(char[] arr, int i, int limit) method
- Java Character codePointAt(CharSequence sequen, int i) Method
Case 1: Java Character codePointAt(char[] arr, int i) method
The code point at the specified index of the char array can be obtained using the Character class's codePointAt() function. The codepoint corresponding to this pair is returned if the char value at an index that is specified is in the low surrogate range, and the following index is much smaller than the index of the char array if the char value at a given index is in the high surrogate range.
Syntax:
public static codePointAt(char[] arr, int i)
- where the index to the char value in the array and the char array are taken as parameters. The codePointAt () function returns the value of the character at the position of the index.
Implementation:
FileName: UnicodeCodePointAtCase1.java
import java.io.*;
import java.util.*;
public class UnicodeCodePointAtCase1
{
public static void main(String[] args)
{
String s = "TutorialAndExample";
// Displays a unicode character at any
// given index in the input string above
// in order to show the use of codePointAt()
int res1 = s.codePointAt(0);
int res2 = s.codePointAt(2);
int res3 = s.codePointAt(4);
int res4 = s.codePointAt(6);
System.out.println("The Original String is given by : " + s);
System.out.println("The unicode point at 0 = " + res1);
System.out.println("The unicode point at 2 = " + res2);
System.out.println("The unicode point at 4 = " + res3);
System.out.println("The unicode point at 6 = " + res4);
}
}
Output:
The Original String is given by : JAVATPOINT
The unicode point at 0 = 74
The unicode point at 2 = 86
The unicode point at 4 = 84
The unicode point at 6 = 79
Case 2: Java Character codePointAt(char[] arr, int i, int limit) method
The code point at a certain index of the char array is returned by the character class's codePointAt(char[] arr, int i, int limit) method, where only the elements having an index less than the limit can be used. The next index is smaller than the limit if, for a given index, the char value contained within the char array is in the highest surrogate range. The code point corresponding to this pair will be returned if the char value at a certain index is in the low surrogate range.
Syntax:
public static intcodePointAt(char[] arr, int i, int limit)
- where the index to the char value in the array and the char array and the index that comes after the last acceptable element in the array is the limit are taken to be as a parameter. The value of the character at the position of the index is returned by the codePointAt() function.
Implementation:
FileName: UnicodeCodePointAtCase2.java
import java.io.*;
import java.util.*;
public class UnicodeCodePointAtCase2
{
public static void main(String[] args)
{
System.out.println("The input is : Tutorialsx");
char[] ch1 = new char[] { 'T', 'u', 't', 'o', 'r', 'i', 'a', 'l', 's', 'x' };
int i1 = 2, limit1 = 9;
int i2 = 4, limit2 = 9;
int result1 = Character.codePointAt(ch1, i1, limit1);
int result2 = Character.codePointAt(ch1, i2, limit2);
System.out.println("The Unicode code point for given input is " + result1 );
System.out.println("The Unicode code point for given input is " + result2 );
System.out.println("The input numbers are: '1', '2', '3', '4', '5' ");
char[] ch2 = new char[] { '1', '2', '3', '4', '5' };
int i3 = 1, limit3 = 4;
int i4 = 3, limit4 = 4;
int result3 = Character.codePointAt(ch2, i3, limit3);
int result4 = Character.codePointAt(ch2, i4, limit4);
System.out.println("The Unicode code point for given input is " + result3 );
System.out.println("The Unicode code point for given input is " + result4 );
}
}
Output:
The input is : Tutorialsx
The Unicode code point for given input is 116
The Unicode code point for given input is 114
The input numbers are: '1', '2', '3', '4', '5'
The Unicode code point for given input is 50
The Unicode code point for given input is 52
Case 3: Java Character codePointAt(CharSequence sequen, int i) Method
The code point at a specific index of the charSequence is returned by the Character class's codePointAt(CharSequence sequen, int i) function. The next index would be shorter than the length of the charSequence if, at a given index, the character value associated with the charSequence is in the high surrogate range. As a consequence, an additional code point corresponding to the specified surrogate pair is returned if the char value that corresponds to charSequence is in the low surrogate range.
Syntax:
public static int codePointAt(CharSequence sequen, int i)
- where the parameters are the list of characters and their corresponding index that needs to be interpreted in sequence. The value of the character at the position of the index is returned by the codePointAt() function.
Implementation:
FileName: UnicodeCodePointAtCase3
import java.io.*;
import java.util.*;
public class UnicodeCodePointAtCase3
{
public static void main(String[] args)
{
System.out.println("Java is a Programming language");
CharSequence seq = "Programming";
int i1 = 2, i2 = 6;
int result1 = Character.codePointAt(seq, i1);
int result2 = Character.codePointAt(seq, i2);
System.out.println("The Unicode code point for given input is " + result1);
System.out.println("The Unicode code point for given input is " + result2);
System.out.println("The input numbers are: '1', '2', '3', '4', '5' ");
char[] ch = new char[] { '1', '2', '3', '4', '5' };
int i3 = 0, i4 = 4;
int result3 = Character.codePointAt(ch, i3);
int result4 = Character.codePointAt(ch, i4);
System.out.println("The Unicode code point for given input is " + result3);
System.out.println("The Unicode code point for given input is " + result4);
}
}
Output:
Java is a Programming language
The Unicode code point for given input is 111
The Unicode code point for given input is 109
The input numbers are: '1', '2', '3', '4', '5'
The Unicode code point for given input is 49
The Unicode code point for given input is 53